With the addition of cover galleries we now support covers of a bigger file size. That's why everyone should strive to add covers of the highest possible quality.
And most of the time (sadly not always) bookwalker has the best covers available. But they are not as easy to access.
Here are two methods on how to get the HQ covers.
As an example we'll take the 10th Slime Isekai cover https://bookwalker.jp/de07d7877c-8409-49a9-9f31-7880e1a74580/
Cover on page: https://rimg.bookwalker.jp/3228813/frDGCemG5kX9EBY8IrbThQ__.jpg
HQ cover: https://c.bookwalker.jp/coverImage_3188222.jpg
Method 1 (the manual method):
1st we find the url of the cover on the page
I made this python one.
1st we find the url of the cover on the page https://rimg.bookwalker.jp/3228813/frDGCemG5kX9EBY8IrbThQ__.jpg
Then add them all to the text file, with every single one on new line. Text file needs to be in the same folder. Then run the code and it will open all the covers as new tab on your browser.
Code:
import webbrowser
with open("textfilenamehere.txt") as f: #<<<replace text file name here
for line in f:
x= line.split("/")
cover_id = str(int(x[3][::-1])-1)
webbrowser.open_new_tab(str("http://cc.bookwalker.jp/coverImage_"+cover_id+".jpg"))
Some covers don't follow "-1" rule. So personally I would recommend "manual" method so if/when you get wrong cover or even "Access Denied" keep doing "-1" until you get proper cover.
Create a new bookmark with this as the URL:
javascript:!function(a){var b=document.createElement("textarea"),c=document.getSelection();b.textContent=a,document.body.appendChild(b),c.removeAllRanges(),b.select(),document.execCommand("copy"),c.removeAllRanges(),document.body.removeChild(b)}("https://c.bookwalker.jp/coverImage_" + (parseInt($('meta[property="og:image"]').attr('content').split("/")[3].split("").reverse().join(""))-1) + ".jpg");
This is freaking awesome. Saves sooo much time, especially when a series goes up to 30+volumes. I tested it on both Chrome and Brave and both work, likely because Brave is also a Chromium-based browser.
Here is a much larger, but feature complete version, following @BzzBzz's suggestion.
After spending a dayweek not doing my HW, I believe this is now a decent tool despite needing some polish.
[ul]Runs on MD in the Covers tab. Upload in 2 clicks without having to save the image to your computer. Volume number auto-fill is WIP. Please verify that the correct number is in there, and add in decimal places as needed.
Also runs on bookwalker site. Unlike the bookmarklet version, this one does not automatically appear into view. Must scroll to the bottom of the page to see it.
Preview video/gif: https://www.youtube.com/watch?v=S1yWrO-dwFg&feature=youtu.be
Note: Recorded with obs, apparently does not support recording cursor on mac. Images underneath 'Copy All Covers' are pulled from bookwalker. Images above are from MD.
More recent example
Features Demonstrated:
[ul]Runs on MD
Follow BW link if it exists. Else, Auto-search BW using the longest Japanese title for the series
Auto fill volume number
Direct Upload. No need to save! I hate saving a file just so I can upload it to some site Basically 2 clicks to upload, since volume field is auto-filled. Just select the cover and push save.
However, do verify the cover matches the preview, the volume number is correct, and that there are no existing uploads using the same volume number. If no bookwalker link is on the page, ensure auto-search came back with the correct series (especially if spinoffs exists).[/ul]
Title Color Codes (WIP):
[ul]
[/ul]
[/ul]
Bookmarklet Version: https://pastebin.com/raw/aCkyHWcS (works in Firefox and Chrome)
[ul]Install Instructions:
1) Open the pastebin link above
2) Select all text on the page via
Code:
ctrl + a
.
3) Copy the text
Code:
ctrl + c
4) Create a bookmark to that text. Make sure the copied text is in the bookmarks location/address/url field.
5) Title it something memorable, eg. "Extract BookWalker Covers"
6) Go to any volume detail page (like from the links above) and click on the bookmarklet. The Cover menu will appear!
This bookmarklet is much longer than the original, but it does quite a bit more. If you think something else is needed, tell me and ill try to add it in. If anyone gets curious, look at Userscript version for the source since the bookmarklet is minified.
Note: If you just want to run this once, you can paste the code into the browser console instead.
Preview image:
[/ul]
Notes:
[ul]Should work in FF and chrome.
Doesn't leave the page.
Will find covers deeper in the list, between minus 0 and minus 15.
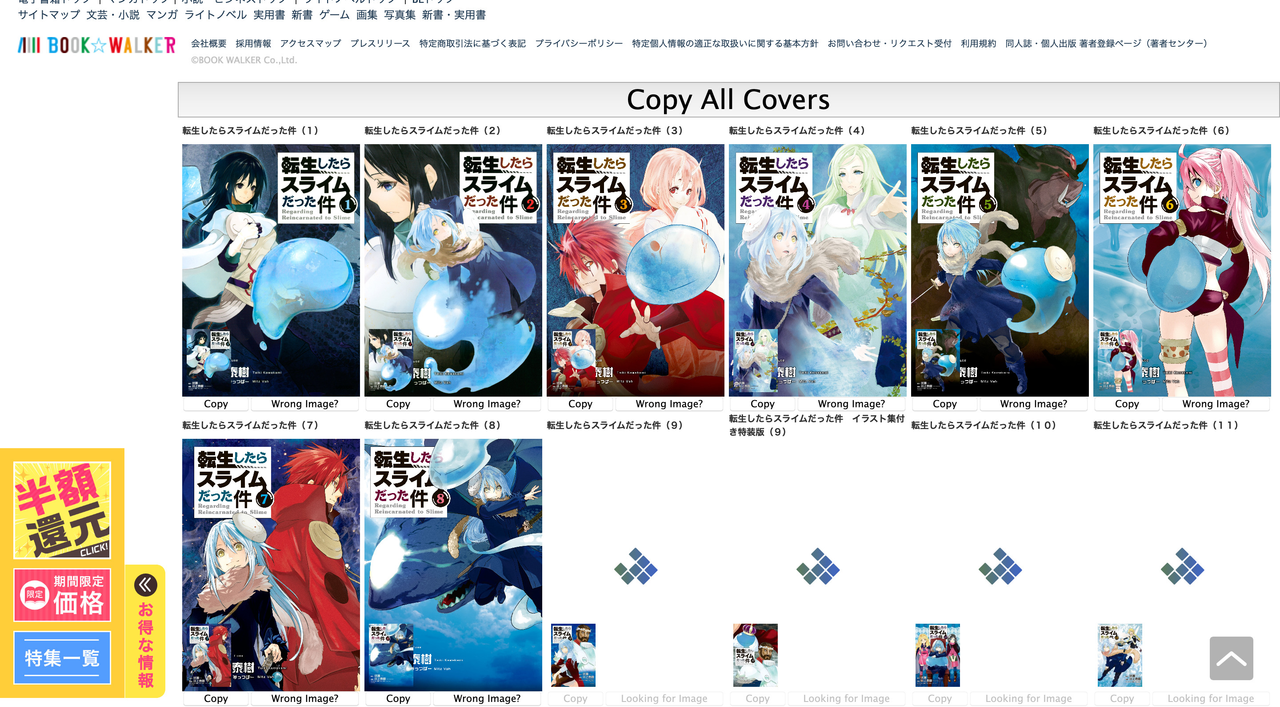
Copy All Covers button! Likely useful for batch extraction of all volume covers (though likely not needed for userscript version). eg. Opening url https://bookwalker.jp/debe5a58ed-c9cb-4cb1-811c-7587aed24cbe/ yields:
Skips most invalid covers (via aspect ratio checks)
Entry: https://bookwalker.jp/de4e5c9652-ab61-43c7-8925-b1851e218936/
Preview: https://rimg.bookwalker.jp/0209871/frDGCemG5kX9EBY8IrbThQ__.jpg
Reversed ID: 1789020
Cover: https://c.bookwalker.jp/coverImage_1789017.jpg
but.... before the cover we get this: https://c.bookwalker.jp/coverImage_1789018.jpg
Exports variables with extra volume/cover data for Browser console use.
[/ul]Current Bugs & Limitations:
[ul]⚠️
Code:
The resulting image is NOT necessarily bookwalker's highest quality cover scan
⚠️ It normally is, at least for more recently uploaded works. I believe the scan is the original version for that seriese. If a higher quality scan is added latter, we wouldn't know. Alternatively, this may be the result of a change in how bookwalker works (meaning all things uploaded before date X have this problem. 180×282 is consistent accross several seriese for the first few volumes. But I do not know how to check what date something was added to bw. date on bw site seems fixed to same date for these seriese thus far.... perhaps I should use that as the cue)
Take, for example, this volume which yeilds this 180×282 cover.
If you click on the volume and open the view trial it yeilds this 764×1200 cover. If anyone knows a good way to find the full quality cover, please tell me.
UI is WIP. Works/looks alright, but is placed at bottom of page. Should integrate it into MD's cover display section and create an overlay for use on bookwalker site.
Limited to extracting covers from the Volume detail pages (like all the links listed above in this thread) and series page.
Intended for wide displays. May induce horizontal scrolling on mobile. (May not work at all on mobile)
Automated cover match checks are WIP. Will work only in userscript version due to restrictive CORS settings. Currently disabled since primitive downsizing function is slow and Pica library isn't working.
Checking a range of 15 is probably overkill.
[/ul]Changelog:
[ul]Now downloads Volume covers one at a time, starting with the first cover. (previously loaded all at once, which didn't work well on slow connections)
Display image dimensions under title
[/ul]TODO:
[ul]✅
Code:
[s](Userscript only) add interface to MD's Cover Upload tab.[/s]
✅
Code:
[s](Userscript only) Upload directly to MD without saving cover to file.[/s]
(Userscript only) Automatically find BookWalker covers from MD title page ✅
Code:
[s]via bookwalker link[/s]
and ✅
Code:
via search (Partial, WIP)
(Userscript only) Automatically detect if MD is using an equal or higher quality cover (via dimension checks, aided by partial-fetch. Grab only first 1KB). Suggest only uploading new and higher quality covers
Code:
(Userscript only) Auto Volume-versioning (add decimal places if multiple covers exist for same volume)
(Partial, WIP)
Code:
(Userscript only) Auto-Detect Non-uploaded covers
(Partial, WIP. Needs a better image comparison library. Color Coded)
✅
Code:
[s](Userscript) Load Non-uploaded volume cover first (Use same code as auto-detect to sort load order).[/s]
(Userscript & Console) Load current volume cover first. (Console, page volume. Userscript, newest volume first).
(Userscript & Console) Ignore 'NOW PRINTING' placeholder covers
(Userscript only) Early rejection of invalid BW aspect ratios via partial-fetch. Not positive if this would be beneficial or not, since it breaks the download down into two requests (first 1KB, check dimensions, then dl all but 1st 1KB). Since it is somewhat rare for another cover to appear before the one we are looking for, it may end up doing more harm than good[/ul]
After installing, Go to any volume detail page and scroll to the bottom. We will find the cover for you.
You can verify the cover by looking at the original preview in the bottom left corner. If we got the wrong cover (rare), click the 'Wrong image?' button and we will look for the next one.
After verifying the cover, click the cover image or the 'Copy' button below it to copy the image url.
Current interface preview below. Note, the bigger ones are the cover images. They are shrunk to a width of 200 and displayed to ensure the correct cover was found. When copied, it will be full size.
More Previews:
Loading icon:
Error icon. LQ Excerpt from
my next choice was the part
Do we have something similar for amazon? If not, here is a small WIP thing I have so far for console use. Works best on the Volume page (not series page). Kindle versions tend to have better covers from what I have seen so far. Just creates images with dimension info above at the bottom of the page atm.
Code:
// Every Hi-ish res image. Assuming id starting with 11 means low res and 91 means hi res. Extracts images with ids matching /^[6-9]1/
//let comicImg
//P.when("ImageBlockATF").execute((b)=>{comicImg=b.imageGalleryData[0].mainUrl}) ;
const iface = document.createElement('div')
iface.style.display='flex'
iface.style.flexFlow='row wrap'
iface.style.alignItems='start'
document.body.appendChild(iface)
Object.values(
//[
//comicImg
//...document.querySelectorAll('img.sims-fbt-image')
//,...document.querySelectorAll('.a-carousel img[data-a-dynamic-image]')
document.querySelectorAll('img')
//]
).map(e=>e.src.match(/\/I\/([^.]+).*\.([^.]+)$/))
.filter(e=>e!=undefined)
.filter(([,id,ext])=>id.match(/^[6789]1/)!=undefined)
.map(([,id,ext])=>`https://images-na.ssl-images-amazon.com/images/I/${id}.${ext}`)
//.concat([comicImg])
.map(url=>{
const img = document.createElement('img')
const imgInfo = document.createElement('div')
img.crossOrigin = "Anonymous"
//fetch(url).then((r)=>r.blob()).then(b=>img.src= URL.createObjectURL(b))
img.src=url
const width = '200px'
img.style.width=width
img.style.minWidth=width
img.style.maxWidth=width
img.onload=()=>{
imgInfo.innerText=`${img.naturalWidth}⨉${img.naturalHeight}`
}
return [img,imgInfo]})
.map(([img,imgInfo])=>{
const cont = document.createElement('div')
cont.style.marginLeft='10px'
cont.style.marginRight='10px'
cont.style.marginTop='15px'
cont.style.display='flex'
cont.style.flexFlow='column nowrap'
cont.style.alignItems='center'
cont.appendChild(imgInfo)
cont.appendChild(img)
iface.appendChild(cont)
return cont})