Dex-chan lover
- Joined
- Mar 2, 2019
- Messages
- 331
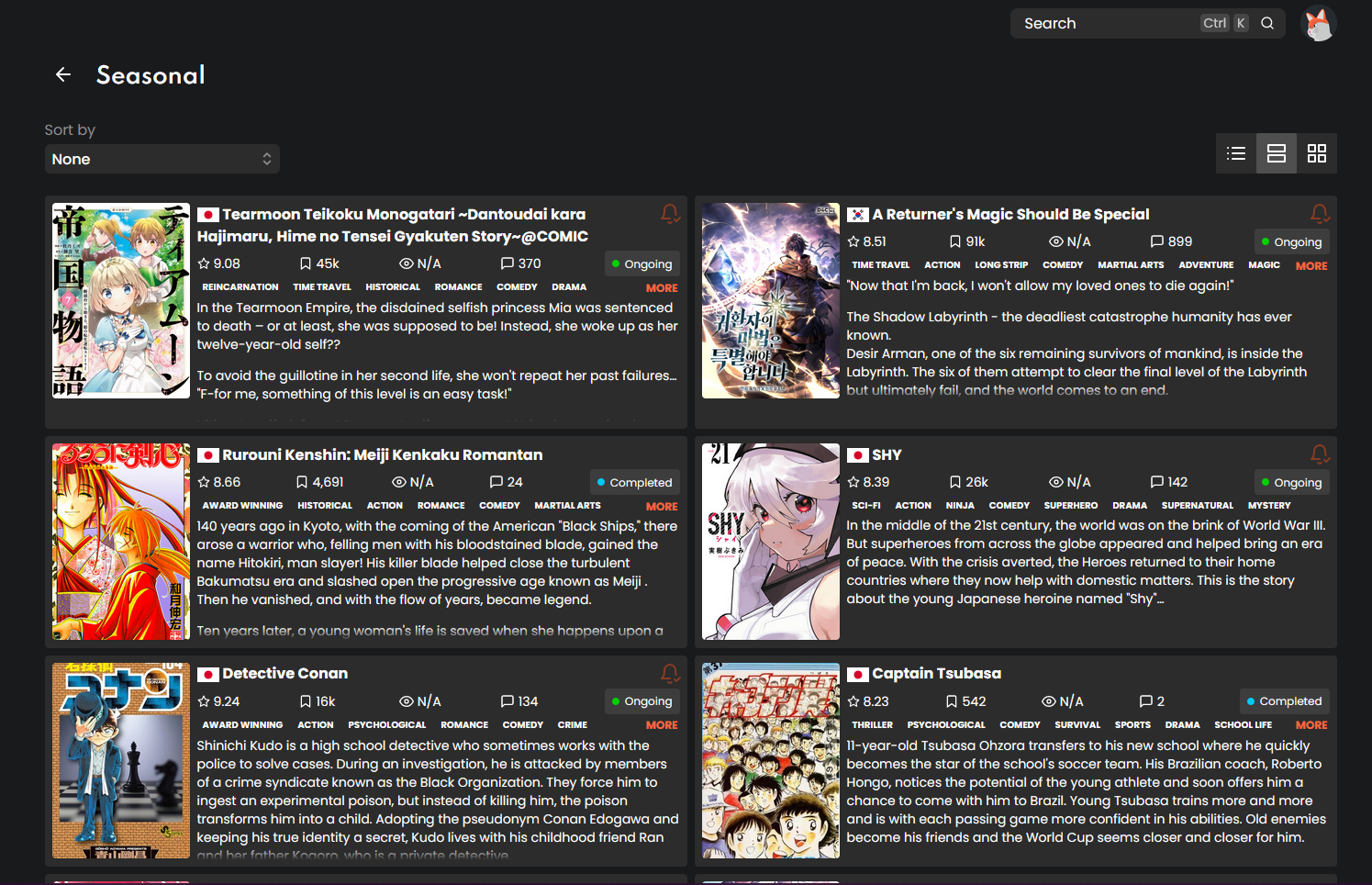
PROBLEM: Sometimes with the advanced search results it takes me a few seconds to realize that I am already reading or have dropped a title because of the frequently changing cover art and even occasional change of the title from JP to EN.
SOLUTION: It would make it easier for me as a user to parse through something like this if, client side, I could gray out mangas I have already read/completed/dropped and just slap an "Opacity: 0.1" on the div.manga-card of the titles which I would choose to display differently from the "Advanced Search" > "Filter" interface. A possible superior alternative might be some little pictograms in the corner which would represent my status with the title but that sounds more work intensive since it modifies layout.
EXAMPLE 1: Attached is an example where "The New Gate" manga would be a part of one of the undesirable selectable categories(mainly Dropped / Completed / Reading / On Pause) The same total number of titles per page remains and the layout is not changed in any way and no extra server requests are made if every result on the whole page is read/dropped/etc. but it is FAR easier for a user to not get stuck on a series he already dropped and not realize until he goes to the titles page and sees its status.
EXAMPLE 2: If you want to see other similar implementations of this solution on bigger platforms you can check it out on "nhentai" if you are over 18 (which I will not link here) by excluding certain languages in your profile and then returning to the home page to see titles belonging to those languages grayed out client side.
Thank you for the great work you've done on this site and have a great day !
SOLUTION: It would make it easier for me as a user to parse through something like this if, client side, I could gray out mangas I have already read/completed/dropped and just slap an "Opacity: 0.1" on the div.manga-card of the titles which I would choose to display differently from the "Advanced Search" > "Filter" interface. A possible superior alternative might be some little pictograms in the corner which would represent my status with the title but that sounds more work intensive since it modifies layout.
EXAMPLE 1: Attached is an example where "The New Gate" manga would be a part of one of the undesirable selectable categories(mainly Dropped / Completed / Reading / On Pause) The same total number of titles per page remains and the layout is not changed in any way and no extra server requests are made if every result on the whole page is read/dropped/etc. but it is FAR easier for a user to not get stuck on a series he already dropped and not realize until he goes to the titles page and sees its status.
EXAMPLE 2: If you want to see other similar implementations of this solution on bigger platforms you can check it out on "nhentai" if you are over 18 (which I will not link here) by excluding certain languages in your profile and then returning to the home page to see titles belonging to those languages grayed out client side.
Thank you for the great work you've done on this site and have a great day !
Last edited:
Upvote
1
 (maybe more expensive on the API?).
(maybe more expensive on the API?).